
 Categories
Categories










































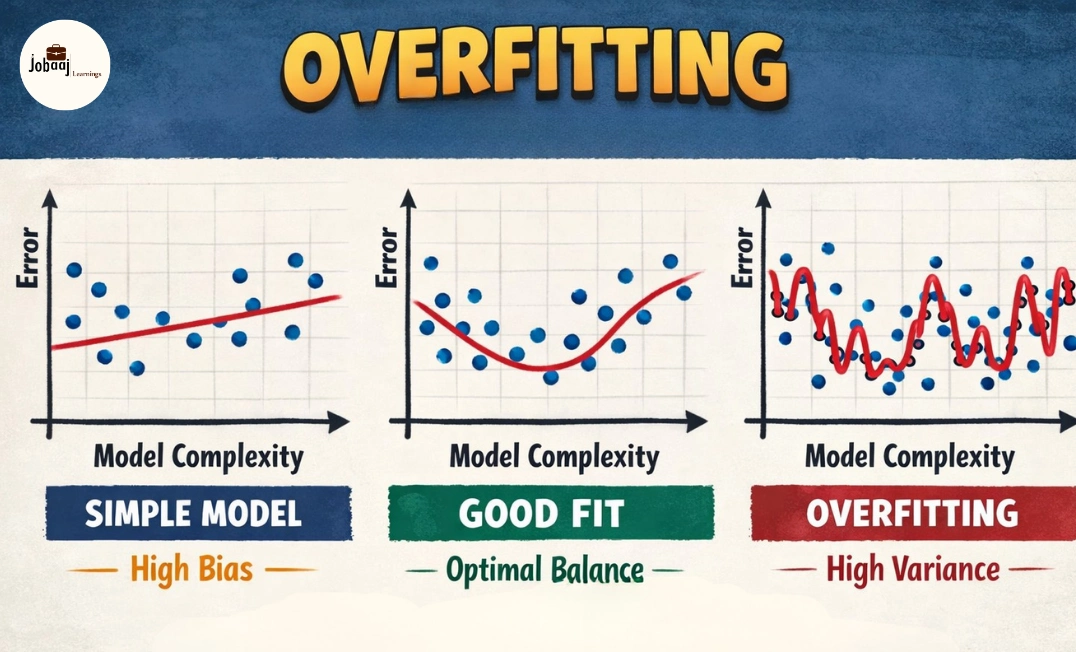
In machine learning, overfitting occurs when a model learns the training data too well, capturing not just the genuine patterns, but also the noise and fluctuations that do not generalize to new, unseen data. When this happens, the model performs exceptionally well on the training dataset but poorly on validation or test datasets. It essentially "memorizes" the training data instead of learning the underlying patterns that can be applied more broadly.
Exploring a career in Data and Business Analytics? Apply Now!
Think of it like studying for a test by memorizing answers instead of understanding the material. You might do well on the test if the questions are exactly the same, but if the questions are phrased differently, you'll struggle.
Overfitting typically occurs when the model is too complex (with too many parameters), the data is too small, or the model is trained for too long without proper validation.
Why is Overfitting a Problem?
Overfitting is problematic because the primary goal of any machine learning model is to generalize well on unseen data. A model that overfits the training data will fail to make accurate predictions when exposed to new data, which renders it useless in real-world scenarios.
Overfitting leads to:
- Low accuracy on new data: Even if the model performs well on the training set, its performance can degrade dramatically on test data.
- Poor generalization: It fails to capture the true patterns in the data and instead focuses on the noise.
- Reduced model robustness: The model becomes highly sensitive to variations in the input data.
Signs of Overfitting
Recognizing overfitting early can save a lot of effort in model training. Here are some common signs of overfitting:
- High training accuracy, low test accuracy: When your model performs great on the training set but significantly worse on the test set, overfitting is likely.
- Excessive model complexity: Complex models (such as deep neural networks with too many layers or decision trees with too many branches) are more prone to overfitting.
- The model has high variance: High variance means that your model is very sensitive to small changes in the input data, which is a classic symptom of overfitting.
How to Prevent Overfitting: Practical Strategies
Here are the best strategies to prevent overfitting and build models that generalize better to unseen data:
1. Cross-Validation
One of the most effective ways to detect and prevent overfitting is cross-validation. Cross-validation splits your data into multiple subsets or "folds" and uses one fold for testing while the rest are used for training. This process is repeated multiple times, with different folds serving as the test set each time.
Types of Cross-Validation:
- K-Fold Cross-Validation: The dataset is split into
ksubsets (folds). The model is trainedktimes, each time using a different fold as the test set and the remaining data as the training set. - Stratified K-Fold Cross-Validation: This version ensures that each fold has the same distribution of classes, especially useful for imbalanced datasets.
- Leave-One-Out Cross-Validation (LOOCV): In this method, one data point is used as the test set, and the remaining data is used to train the model. This is computationally expensive but can be useful for small datasets.
How it helps: Cross-validation ensures that your model performs well across different subsets of data, which helps in detecting overfitting early and ensures that your model can generalize to unseen data.
2. Regularization
Regularization is a technique used to reduce the complexity of the model by penalizing large coefficients in regression models. This helps to prevent overfitting by discouraging the model from fitting the noise in the data.
- L1 Regularization (Lasso): This technique adds a penalty to the absolute values of the model's coefficients. It has the effect of shrinking some coefficients to zero, effectively performing feature selection.
- L2 Regularization (Ridge): This adds a penalty to the squared values of the coefficients. L2 helps reduce the impact of irrelevant features without eliminating them completely.
Both L1 and L2 regularization can help in creating simpler models that are less prone to overfitting, especially when dealing with large datasets.
How it helps: Regularization forces the model to be simpler and less prone to capturing noise, improving its generalization on new data.
3. Simplify the Model
A common cause of overfitting is an overly complex model. When the model has too many parameters or layers (in the case of deep learning), it becomes more likely to fit the noise in the training data. Simplifying the model can help prevent this.
- Reduce the number of features: Perform feature selection to keep only the most relevant features for prediction.
- Reduce model complexity: For decision trees, you can limit the depth of the tree or set a minimum number of samples per leaf.
- Use simpler models: For example, using linear regression instead of a high-degree polynomial regression can help prevent overfitting.
How it helps: A simpler model focuses on the core patterns in the data rather than fitting noise, which leads to better generalization.
4. Increase the Size of the Dataset
A small dataset is more likely to result in overfitting, as the model has fewer examples to learn from. Increasing the size of the dataset is one of the most effective ways to prevent overfitting.
If collecting more data is not feasible, you can also use data augmentation (particularly in image and text data) to artificially increase the size of the dataset by generating modified versions of the existing data points.
How it helps: More data allows the model to learn more general patterns and reduces the risk of overfitting to a small, unrepresentative sample.
5. Early Stopping
When training deep learning models, early stopping is a technique that can help prevent overfitting. It involves monitoring the model's performance on a validation set during training. If the model’s performance starts to degrade on the validation set, even though it continues to improve on the training set, training is stopped early.
How it helps: Early stopping ensures that the model doesn't continue to memorize the training data and start overfitting, as training is stopped at the point where the model performs best on unseen data.
6. Dropout
Dropout is a regularization technique used in neural networks where, during each training iteration, a random subset of neurons is ignored (set to zero). This prevents the network from becoming overly reliant on any single neuron and forces the network to learn more robust features.
How it helps: Dropout prevents overfitting by ensuring the model doesn’t rely too heavily on specific neurons, improving its ability to generalize on new data.
7. Ensemble Methods
Ensemble methods combine multiple models to improve overall performance. These methods can help reduce overfitting by averaging out the predictions of multiple models, thus reducing the variance of the predictions.
- Bagging (Bootstrap Aggregating): In bagging, multiple models are trained on different random subsets of the data, and their predictions are averaged. Random Forest is an example of a bagging method.
- Boosting: In boosting, models are trained sequentially, where each new model corrects the errors of the previous one. Examples of boosting algorithms include XGBoost and AdaBoost.
How it helps: By combining several models, ensemble methods reduce the chance of overfitting to noise in the data, leading to a more robust and generalized model.
8. Cross-Feature Regularization
When working with datasets that contain features that interact with each other, cross-feature regularization can help by adding penalties for these complex interactions. This prevents the model from overly fitting the data based on feature interactions that are not generalizable.
How it helps: By discouraging overly complex interactions between features, the model becomes less sensitive to noise and more likely to generalize well to unseen data.
Conclusion
In machine learning, there’s always a tradeoff between bias (the error introduced by simplifying the model) and variance (the error introduced by overfitting to the training data). The goal is to find a balance that minimizes both bias and variance, resulting in the best-performing model for unseen data.
By using techniques like cross-validation, regularization, and simplifying your model, you can effectively prevent overfitting and create models that generalize well to real-world data. Prevention is key in ensuring that your model performs optimally not just on the data it’s trained on, but on new, unseen data as well.
By carefully monitoring the training process and using the right strategies, you can ensure that your machine learning models are robust, accurate, and reliable.
Aspiring for a career in Data and Business Analytics? Begin your journey with a Data and Business Analytics Certificate from Jobaaj Learnings.





